Retour à l'accueil
MEMOIRE NAGIOS/SNMP
(Ceci est un résumé bien entendu)
(En date de Juin 2003)
SOMMAIRE
INTRODUCTION
1. Sujet du Stage
Mise à jour du logiciel de
supervision Netsaint vers sa dernière version appelée
Nagios.
Mise en place du protocole SNMP sur
les serveurs Windows NT 4.0, 2000 et Citrix.
Mise en place du protocole SNMP pour
la surveillance des Routeurs et Switchs.
Utilisation des logiciels
complémentaires NTOP, Cricket (type MRTG).
Apprentissage des tâches
d'administration réseau.
2. Cahier des Charges
Le but prioritaire du projet sera d'avoir une station de
surveillance du réseau qui remplisse les conditions suivantes
:
Outre cela, différents logiciels supplémentaires
pourront être testés pour contribuer à la
réalisation de cet objectif.
Le but est de pouvoir récupérer des
informations précises permettant la détection de panne,
l'indisponibilité des serveurs et de leurs services ou encore
la charge du réseau.
Il faut également pouvoir anticiper les problèmes
que les utilisateurs peuvent rencontrer pour ce qui est de l'accès
aux services réseaux en limitant le temps de réaction
de l'administrateur au minimum.
En outre, le rajout, la suppression et la configuration
de nouveaux matériels devraient se faire facilement et
rapidement.
Le tout doit être réalisé dans un
souci d'économie maximum sur le plan financier.
L'outil de supervision existant était Netsaint
installé depuis environ un an sous une Linux Mandrake 8.2. Il
avait été mis en place pour avoir une première
expérience des logiciels de supervision de réseau et
pour décider si cela pouvait devenir une solution pérenne.
Netsaint ayant fait ses preuves de fiabilité et
d'efficacité, il fut décidé de continuer avec
son successeur, Nagios (disponible depuis Novembre 2002).
Ce logiciel, associable au protocole SNMP (définit
plus loin), permet une plus grande personnalisation des contrôles
que l'on désire effectuer.
Nagios est un logiciel de supervision des systèmes
et des réseaux.
Il supervise des hôtes (serveurs, stations de
travail, routeurs, ...) et des services (http, ftp, smtp, pop3, ...).
Cependant, il ne fait pas d'analyse de trafic, de reniflage de
paquet, etc. Nagios est en fait l'évolution de Netsaint,
auquel de nouveaux outils ont été ajoutés et de
nombreuses corrections apportées.
Le but principal de Nagios est de surveiller les
services qui fonctionnent sur la machine et qui sont fournis par les
serveurs ou les dispositifs physiques du réseau. Il est
évident que si un serveur ou un dispositif sur le réseau
est hors service, tous les services qu'il offre sont également
indisponibles. De même, si un serveur devient inaccessible,
Nagios ne pourra pas surveiller les services qui lui sont liés.
Nagios identifie et essaye de vérifier si un
problème sur un service correspond à un scénario
existant. Dès qu'un contrôle de service atteint un
niveau non satisfaisant, Nagios essayera de vérifier si le
serveur et le service en cours sont toujours opérationnels.
C'est en « pingant » le serveur et en voyant si
une réponse est donnée que l'alerte est déclenchée
si le besoin s'en fait sentir.
Nagios n'informe que les contacts concernés des
problèmes d'un serveur ou de son inaccessibilité. Si la
commande de contrôle du serveur renvoie un état OK,
Nagios identifiera que le serveur est fonctionnel et enverra
seulement une alerte pour le service qui pose problème.
Il est tout
à fait possible depuis un poste Windows de surveiller
à distance l'état général
du réseau et d'accéder à l'interface
graphique Web de Nagios avec NTRAY.
Dans les annexes sont mentionnées les procédures
d'installation des fichiers sources, du serveur web ainsi que du
protocole SNMP. Ce qui suit s'applique à l'OS Mandrake 9.1.
Le fichier de configuration principal se situe selon
cette arborescence : /etc/nagios/nagios.cfg. Il contient diverses
variables de configuration. On peut laisser la configuration par
défaut, cependant, il est nécessaire de changer
l'adresse mail de l'administrateur pour qu'il soit contacté en
cas de problème.
Ensuite, il faut configurer les fichiers liés à
l'utilisation des CGI. Les CGI sont des scripts utilisés par
un serveur Web pour afficher des valeurs stockées dans une
base de donnée via un navigateur web. Il faut créer un
alias pour les CGI afin de rendre les fichiers html accessibles via
le serveur web. Pour cela, il est nécessaire de modifier le
fichier nagios-httpd.conf (/etc/httpd/conf) et de créer le
fichier .htaccess (usr/lib/nagios/cgi/.htaccess) en suivant
exactement la documentation de Nagios.
Ne pas oublier l'étape de création du
fichier htpasswd.users dans le répertoire /usr/lib/nagios avec
un utilisateur (comme nagiosadmin) et un mot de passe. La dernière
chose à vérifier étant le fichier cgi.cfg de
Nagios (/etc/nagios/cgi.cfg) en particulier les lignes suivantes :
use_authentication = 1
authorized_for_system_information = nagiosadmin
authorized_for_configuration_information = nagiosadmin
authorized_for_system_commands = nagiosadmin
authorized_for_all_services = nagiosadmin
authorized_for_all_hosts = nagiosadmin
authorized_for_all_service_commands = nagiosadmin
authorized_for_all_host_commands = nagiosadmin
Si un problème de lecture des fichiers de log se
présente, il faut s'assurer que le propriétaire est
bien Nagios et que les droits soient en lecture/écriture.
Il y a certaines modifications à faire dans ce
fichier en plus de celles déjà mentionnées
précédemment. Par exemple, si l'on veut ajouter des
images et des icônes dans les cgi d'état, de
cartographie des états, du monde des états et
d'informations complémentaires, il faut intervenir en
modifiant cette ligne :
physical_html_path=/usr/share/nagios/images -> mettre le bon chemin !
Et ces deux lignes sont à rajouter :
xedtemplate_config_file=/etc/nagios/hostextinfo.cfg
xedtemplate_config_file=/etc/nagios/serviceextinfo.cfg
Ces deux fichiers « hostextinfo.cfg »
et « serviceextinfo.cfg » sont à créer
dans /etc/nagios.Le premier contiendra les icônes et images
associées aux hôtes, l'autre celles pour les services.
On déclare dans les fichiers hosts et hostgroups
tous les serveurs, routeurs, stations, ... qui sont connectés
au réseau et dans le fichier services les services à
contrôler. On configure le fichier « hostgroups »
pour définir les groupes dont fera partie chaque hôte :
define hostgroup {
hostgroup_name D - Autres Serveurs
alias Autres Serveurs
contact_groups linux-admins
members TEST
}
Le serveur « TEST » mentionné
ci-dessus sera membre d'un groupe, ici « D - Autres
Serveurs », et les notifications d'incidents seront
envoyées à un groupe de contact, ici « linux-admins ».
On configure le fichier « hosts » :
define host {
host_name TEST
alias Serveur Divers
address 192.10.20.20
check_command check-host-alive
max_check_attempts 10
notification_interval 120
notification_period 24x7
notification_options d,u,r
}
Le serveur « TEST » a l'adresse IP
192.10.20.20 ; on utilise la commande « check-host-alive »
pour s'assurer de son bon fonctionnement ; le chiffre 10 représente
le nombre de fois que nagios relancera la commande de contrôle
du serveur ; le chiffre 120 représente l'intervalle de
re-notification d'un incident à un groupe de contact ; 24x7
(24heures/24 et 7jours/7) est la période durant laquelle les
notifications d'événements seront émises vers le
groupe de contact rattaché au serveur ; enfin, les options de
notifications : d(own-tombé), u(nreachable-inaccessible),
r(ecovery-retablit).On configure le fichier « services »
:
define service {
host_name TEST
service_description HTTP
is_volatile 0
check_period 24x7
max_check_attempts 3
normal_check_interval 5
retry_check_interval 1
contact_groups linux-admins
notification_interval 120
notification_period 24x7
notification_options w,c,r
check_command check_http
}
Le service « HTTP » est surveillé
sur le serveur « TEST » ; ce service n'est pas
« volatile » (se dit d'un service qui génère
des journalisations (logs) et des notifications à chaque fois
qu'il est contrôlé), il est de type normal ; période
de contrôle de 24h/24 et 7j/7 ; nagios réessayera de
contrôler ce service 3 fois suite à un incident ;
contrôle normal toutes les 5 minutes ; délai d'1 minute
avant de lancer le prochain contrôle normal après avoir
atteint les 3 essais de contrôle ; « linux-admins »
est le groupe de contact à notifier avec un intervalle de
re-notification de 120 minutes, sur une période de 24h/24 et
7j/7, avec les options de notifications de w(arning-attention),
c(ritical-critique) et r(ecovery-retablit) ; « check_http »
est la commande exécutée par nagios pour vérifier
l'état de ce service.
On déclare dans le fichier suivant les contacts
permettant d'identifier la personne qui doit être contactée
lors d'un problème sur le réseau. On configure le
fichier « contacts » :
define contact {
contact_name nagiosadmin
alias Administrateur Nagios
service_notification_period 24x7
host_notification_period 24x7
service_notification_options u,c,r
host_notification_options d,u,r
service_notification_commands notify-by-email
host_notification_commands host-notify-by-email
email user@localhost
}
On indique le nom du contact ; le contact sera notifié
des incidents liés au service 24h/24 et 7j/7 ; le contact sera
notifié des incidents liés à l'hôte 24h/24
et 7j/7 ; voir + haut pour les options de notifications de service et
d'hôte u(nreachable-inaccessible), c(ritical), d(own),r ;
commande de notification (ici par e-mail) à utiliser pour
avertir d'un incident (service et hôte) ; adresse email du
contact. On configure aussi le fichier « contactgroups »
:
define contactgroup {
contactgroup_name linux-admins
alias Administrateurs linux
members nagiosadmin
}
On indique le nom du groupe et ses membres.
Information supplémentaire
:
Pour
configurer nagios, on peut également se
servir de NAGAT (NAGios Administration Tools), un module écrit
en PHP, à
télécharger, qui utilise une interface graphique dans un
navigateur Web ainsi que de NAGMIN, module dépendant de WEBMIN,
associé à une base de donnée.
Le serveur retenu est Postfix. Sa configuration est
accessible via Webmin,
Onglet Serveurs. Les champs suivants sont à modifier dans
/etc/postfix/main.cf :
« myhostname »
: ajouter le nom de la station sur laquelle est installée
Nagios (récupérable avec la commande hostname en
mode console)
« myorigin »
et « mydestination » : laisser par défaut
mais dé commenter ces deux lignes
« relayhost »
: ajouter l'adresse du serveur de messagerie
En mode console, on peut tester la bonne configuration
du serveur avec la commande « postfix check ».
On peut relancer le daemon avec la commande « postfix
reload ». Maintenant, on peut vérifier l'envoi et
la réception de mails en local en mode console avec la
commande mail.
Ensuite,
on configure Nagios pour qu'il expédie les mails d'alerte
(fichier "misccommands" avec commandes "notify-by-email" et
"host-notify-by-email").
Autre méthode, on peut installer un serveur
POP3 permettant la récupération des mails par un logiciel de mail distant (comme MS Exchange par exemple).
Pour ce faire :
installer
le paquetage imap-2001a-9mdk contenant les fichiers
nécessaires pour le fonctionnement des serveurs pop et
imap
redémarrer
le serveur xinetd qui contrôle le daemon ipop3
vérifier
par un netstat que le port est bien en « listen »
Dans un logiciel de messagerie, il suffit d'ajouter une
nouvelle source de message. Avec MS Exchange, cliquer sur le menu
Outils->Services d'Outlook, cliquer sur Ajouter->Messagerie
Internet pour récupérer les mails de la boîte à
lettre distante par le protocole POP3.
A la différence de beaucoup d'autres outils de
supervision, Nagios ne dispose pas de système interne pour
vérifier l'état d'un hôte ou d'un service. A la
place, il utilise des programmes externes (appelés plugins)
pour exécuter ces vérifications. Nagios commande
l'exécution de ces programmes et ceux-ci lui retournent les
résultats de leurs contrôles. Voici un exemple des
principaux plugins disponibles :
« check_tcp,check_pop,check_smtp,check_ping,check_disk,check_http,... »
Grâce
à cette architecture, on peut contrôler tout ce que l'on
veut
puisque si il n'existe pas de plugins adapté, il est possible
d'écrire soi-même un petit script bash ou perl. Voir en
annexe le principe de fonctionnement.
Je fais ici une présentation sommaire de
l'interface graphique en utilisant une traduction des mots anglais.
General
Les deux liens Accueil et Documentation
renvoient respectivement à la page d'accueil et à la
documentation complète de Nagios en Anglais.
Ces liens sont internes et il n'est pas nécessaire
d'avoir un accès Internet pour avoir accès à la
documentation par exemple.
Monitoring
Vue Générale: C'est une vue globale
de tous les éléments contrôlés par Nagios
: réseau, hôtes, services, contrôles, surveillance
du dispositif, etc... On voit ainsi d'un seul coup d'oeil si tout
fonctionne bien ; on peut rester sur cette page en temps normal.
Détail des Services
: C'est une vue détaillée de chacun des services
contrôlés pour chaque hôte. Toutes les
informations de contrôle y sont mentionnées.
Détail des Hôtes :
Vue détaillée de tous les hôtes supervisés
et des contrôles en cours.
Vue par Groupe : Comme son nom l'indique, il
s'agit d'une vue qui rassemble les hôtes selon des groupes que
l'on a définis dans les fichiers de configuration. Elle
mentionne le nom des hôtes, leur état, le nombre de
services qui leur sont rattachés et des liens pour effectuer
certaines actions (informations détaillées et accès
à la page de gestion des contrôles).
Vue sommaire
: Seul les groupes sont indiqués avec, pour chacun, le nombre
d'hôte et le nombre de services qui leur sont rattachés
(et contrôlés).
Vue Groupe et Services
: C'est une vue semblable à la vue par Groupe, la
différence majeure est que chaque service y est mentionné
par son nom et sous la forme de tableaux faciles à lire.
Carte 2D
: Chaque hôte y est représenté par une image
graphique et le simple fait de laisser le pointeur de la souris sur
l'une d'elle
fait apparaître des informations sommaires.
Problèmes sur Services : Indique tous les
services qui posent problèmes.
Problèmes sur Hôtes
: Indique tous les hôtes qui posent problèmes.
Pannes Réseau :
Indique les liens réseaux qui provoquent l'inaccessibilité
Commentaires : Permet d'ajouter des commentaires
sur un hôte ou un service (utile par exemple pour indiquer à
d'autres personnes que l'on va arrêter un serveur pour
maintenance) .
Temps d'Arrêt Programmé :
Permet d'arrêter l'envoi de notifications durant un temps fixé.
Informations Processus : Informations et
commandes possibles sur le processus Nagios lui-même.
Informations Performances : Informations sur les
contrôles actifs et passifs.
File d'Attente Contrôles : Ordre suivant
lequel Nagios effectue ses différents contrôles.
Reporting
Tendances : Permet d'avoir un état
graphique selon la date et le statut (« up »,
« down », « unreachable »,
« indeterminate ») de chaque hôte ou
service spécifié.
Disponibilités : Permet d'avoir un rapport
sous la forme de tableaux et de statistiques. Il est possible d'avoir
une vue par Groupe d'hôtes également.
Histogramme des Alertes :
Représentation graphique de la disponibilité d'hôtes
ou de services sur une période de temps paramétrable.
Historique des Alertes : Visualisation des
événements importants sous la forme d'un listing
reprenant le fichier de log.
Alertes Récentes : Affichage des alertes
les plus récentes.
Notifications : Indique le type de notifications
envoyées aux contacts mentionnés.
Logs :
Affiche tout le fichier de log.
Configuration
Visualisation : Affichage
de toute la configuration d'un objet spécifié : hôte,
service, contacts, périodes de contrôles, commandes,
etc...
Suite au plantage de la station de surveillance, Nagios
peut se bloquer en raison des fichiers de commandes externes. Ceux-ci
se trouvent dans /var/spool/nagios. En cours d'utilisation, il est
normal qu'un ou plusieurs fichiers de commandes soient présents
dans ce répertoire. Par contre, lorsque Nagios est stoppé,
il ne doit plus y en avoir aucun sinon, au re-démarrage,
Nagios se bloque sur ces fichiers existants. Il ne peut pas créer
un fichier qui existe déjà.
Module écrit en Perl pour les systèmes
d'exploitation Windows qui permet l'affichage d'une icône dans
la barre des tâches. Celle-ci change de couleur (rouge, jaune,
orange ou vert) selon l'état des services. Cet utilitaire peut
être installé sur tous les postes des administrateurs et
se sert du serveur Nagios pour accéder directement à la
page d'accueil (utilise le service http).
Voir le site de Nagios ->
http://www.nagios.org/download/extras.php.
Module écrit en PHP qui utilise une interface
graphique dans un navigateur Web pour configurer les hôtes et
les services sans passer par la modification directe dans les
fichiers.
Suite à différents tests effectués,
on peut constater que les imports/exports ont quelques problèmes
et que les champs ne correspondent pas toujours aux options qui
existent dans les fichiers de configuration, prudence donc avec cette
version alpha et à utiliser avec précaution !
Personnellement, j'ai décidé de configurer Nagios
uniquement en éditant les fichiers textes qu'il utilise (http://sourceforge.net/projects/nagat/).
NAGMIN est un module de
WEBMIN programmé en Perl pour l'administration de Nagios. NAGMIN
ajoute
des fonctionnalités à Nagios avec des dispositifs uniques
de configuration en liaison avec une base de données et NMAP
pour la découverte de réseau et le scan
de ports.
Attention, outils en cours d'amélioration, à utiliser avec précaution (http://nagmin.sourceforge.net/ et
http://sourceforge.net/projects/nagmin).
Nagios n'est pas un gestionnaire SNMP, cependant, on
peut utiliser ce protocole, soit via le plugin "check_snmp"
qui utilise la commande snmpget soit via un script Perl, pour
contrôler certains services ainsi que gérer des
remontées d'alertes (traps snmp).
Sur la machine distante, il est important d'avoir
installé puis activé le service SNMP. Ce service
utilise le port 161 pour les échanges de requêtes/réponses
et le port 162 pour les traps.
Sur la station
de surveillance, seul snmptrapd,
qui réceptionne les traps (snmpd gère les requêtes
en provenance d'une machine distante donc inutile sur celle-ci), doit
être actifs (si on
reçoit des traps bien sûr !). On peut
tester le bon fonctionnement de ces processus en ligne de commande
par un snmpget, un snmpwalk ou un snmptrap comme décrit dans les
annexes.
A l'aide du protocole SNMP, le but recherché
était d'atteindre davantage de service(s) pour pouvoir les
contrôler ainsi que de pouvoir envoyer des traps dès
qu'un problème surgissait. Ceci, sans pour autant installer
des logiciels supplémentaires.
Le premier objectif fut atteint grâce au plugin
check_snmp et la documentation écrite par Xavier Dusart
intitulée "Comment je supervise des serveurs NT" et, pour W2k
ici.
Le test a été fait concernant la mémoire
physique disponible, la charge CPU et l'espace disque. En voici les
étapes pour la mémoire physique disponible :
1°) Le service « MEM » a été
déclaré comme suit :
define service {
name MEM
service_description Memoire_Disponible
check_period 24x7
max_check_attempts 3
normal_check_interval 2
retry_check_interval 1
contact_groups linux-admins
notification_interval 0
notification_period 24x7
notification_options w,c,r
check_command check_memory_nt!35000000!20000000
register 0
}
On peut noter avec intérêt
que cette commande possède deux paramètres. Le premier
chiffre (35000000 octets – 35 Mo) indiquera à Nagios la
valeur à partir de laquelle ce service passera en état
de warning et le second chiffre (20000000 octets – 20 Mo) la
valeur à partir de laquelle le service sera considéré
en état « critical ».
2°) Dans le même fichier, on relie ce service
à un hôte existant :
define service {
use MEM
host_name TEST
}
3°) Dans le fichier "checkcommands", on
définit la commande déclarée précédemment
:
define command {
command_name check_memory_nt
command_line $USER1$/check_snmp -H $HOSTADDRESS$ -o .1.3.6.1.4.1.311.1.1.3.1.1.1.1.0
-w $ARG1$:0 -c $ARG2$:0 -l "Mémoire Physique Disponible" -u "bits"
}
Note Importante : Pour cette commande ($ARG1$:0
soit max:min), un état OK sera retourné si le résultat
est en dehors de la plage spécifiée, un état non
OK si le résultat est dans la plage (limites inférieure
et supérieure incluses).
Il a été nécessaire de recourir à
des scripts Perl dans certains cas.
Le premier était lié au service de spool.
Lorsque le service est actif, on peut le voir selon cette
arborescence dans la MIB Microsoft LanMgr :
La
difficulté était que cette valeur
n'était plus disponible à l'arrêt du service donc
Nagios affichait un état "unknow" pour ce service.
Il fallait lui indiquer un état "critical" à la place,
d'où le recours à un script Perl disponible dans les
annexes.
Les traps servent à envoyer une valeur stockée
dans la MIB depuis un agent (serveur, routeur, ...) vers une station
d'administration pour lui signaler un problème comme l'arrêt
d'un service, un reboot, etc...
D'après mes recherches, en particulier sur le
site de Microsoft, aucune application n'est installée par
défaut sur les serveurs Windows qui permette de traduire une
alerte en trap. Par contre, il est possible de les générer
sur les serveurs Citrix. Un trap standard SNMP version 1 peut-être
envoyé avec cette commande :
snmptrap -dv 1 192.10.10.02 public 0 192.10.10.11 6 0 '' 0 s "coucou"
L'option -d est une option de deboggage qui permet de
visualiser le trap que l'on a envoyé, l'option -v va avec le
chiffre suivant 1 qui indique la version du protocole utilisé
(ici snmp version 1). L'adresse 192.10.10.02 est celle du
destinataire du trap (ou manager).
Il faut indiquer ensuite la communauté, par
défaut c'est « public ». C'est LA faille
de sécurité du protocole SNMP car elle apparaît
en clair sur le réseau et tout bon sniffer la fait apparaître.
Quand on connaît le nom de la communauté, on peut très
librement accéder à toute la table MIB d'un hôte
sur le réseau et récupérer des infos précieuses
sur celui-ci (OS, partages, adresses IP,...).
Le chiffre après la communauté ( ici 0 )
est l'identifiant, ou OID, de l'entreprise ( 77(réseau) et
311(système) pour Microsoft (+ 3845 pour citrix)).
La console de management des serveurs Citrix permet
l'activation et l'envoi de traps SNMP vers une station spécifique,
j'ai donc fait des tests avec ces serveurs.
Voici les étapes d'émission et de
réception d'un trap en provenance d'un serveur Citrix vers
Nagios :
traphandle default echo "[`date +%s`] PROCESS_SERVICE_CHECK_RESULT;CITRIX03;AlertesCitrix;2;
Charge CPU dépassée" >> /var/spool/nagios/nagios.cmd
Quelques explications :
Pour la commande Nagios :
Ici, tous les traps provoquent cette alerte, ce qui est
inutile. On veut générer des alertes en fonction du
trap reçu. Or, les traps avec un OID spécifique ne sont
pas reconnus par le daemon snmptrapd lorsqu'ils sont envoyés
sous le format de la version 1. Il est donc nécessaire de
passer par un script perl jouant le rôle de gestionnaire des
traps qui alertera Nagios selon les indications mentionnées
dans les traps :
traphandle default /etc/snmp/gestion_traps
Ce script est disponible sur demande.
En associant Nagios et SNMP, on arrive à
configurer une station de surveillance fiable et fonctionnelle.
Dans ce rapport, tout n'a pas été dit sur
Nagios et les nombreuses possibilités qu'il offre à la
fois dans son fonctionnement interne et aussi sur les nombreux
plugins qu'il recèle sans parler de ceux que l'on peut
développer.
Il est possible aussi de développer de nombreux
compteurs supplémentaires et les ajouter dans une MIB qui
deviendra une branche de la MIB principale.
Suite à la réalisation de cette station,
de nombreux problèmes ont été soit évités,
soit pris en charge à temps.
Par exemple, des services ont pu être redémarré
rapidement sans qu'une avalanche de personnes mécontentes
n'appellent pour savoir pourquoi elles ne pouvaient plus accéder
à leurs applications préférées.
L'objectif était de disposer d'une station de
supervision fiable et adaptée au réseau de
l'entreprise. Elle devait répondre aux critères
suivants :
L'implémentation de Nagios fut un succès
sous ces différents rapports.
Le coût financier fut quasi nul.
La fiabilité, déjà constatée
avec son prédécesseur Netsaint, fut confirmée suite à
de nombreux tests et une mise en charge progressive.
A la suite d'une erreur de manipulation, des fichiers
furent supprimés mais cela permit de constater qu'en quelques
heures le système était reconstructible à la
condition d'avoir sauvegardé les fichiers de configuration.
L'évolutivité peut se constater dans les
annexes sous la partie Evolutions et Améliorations possibles.
Enfin, chaque contrôle est paramétrable de
manière précise et adapté à ce que l'on
veut superviser.
Je me permets, dans cette partie, de traiter des
différents logiciels de supervision multi environnement
(Unix Linux Windows) existant, de faire un bref rappel des besoins
exprimés puis d'indiquer pourquoi Nagios a été
utilisé dans le cas précis du réseau de cette
société.
Je me dois de souligner que cette partie n'a pas la
prétention de traiter de toutes les solutions de
supervision qui existent sur le marché mais d'en mentionner
les principales dans le but de montrer pourquoi celle qui a été
utilisée a été retenue.
Voici un tableau résumé des logiciels
propriétaires de supervision :
|
Des offres centrées sur la supervision
réseau.
|
|
Éditeur
|
|
Offre
|
|
Fonctions
|
|
Équipements acceptés
|
|
Prix à partir de (HT)
|
|
|
|
|
|
|
|
|
|
|
|
Computer Associates
|
|
Network IT
|
|
Supervision, configuration des VLAN,
intégration d'outils de configuration tiers
|
|
Toutes marques
|
|
7 927 €
(52000F)
|
|
|
|
|
|
|
|
|
|
|
|
HP
|
|
OpenView Express
|
|
Supervision, intégration d'outils de
configuration tiers
|
|
Toutes marques
|
|
38 112 €
(250 000 F)
|
|
|
|
|
|
|
|
|
|
|
|
IBM
|
|
Tivoli
|
|
Supervision, intégration d'outils de
configuration tiers
|
|
Toutes marques
|
|
38 112 €
(250 000 F)
|
|
|
|
|
|
|
|
|
|
|
|
Quest Software
|
|
Big Brother
|
|
Supervision, intégration d'outils de
configuration tiers
|
|
Toutes marques
|
|
Gratuit en partie
|
Les caractéristiques sommaires de ces différentes solutions sont exposées maintenant :
Voici le commentaire d'une personne l'ayant testé
:
« Unicenter, logiciel de supervision
multi environnement, est composé d'un module appelé
Manager qui paramètre les agents et réceptionne les
résultats des mesures effectuées par ces mêmes
agents. Il existe un Manager par brique fonctionnelle (OS,
serveur...).
Pour nos tests nous avons installé la brique
surveillance système. Les règles de surveillance sont
dictées à l'agent par le biais d'un fichier. Lors d'une
alerte, l'agent renvoie la notification au Manager. Ce dernier va
chercher dans une base, les règles à exécuter en
cas de dépassement de seuil.
Les informations remontées en temps réel
sont assez complètes. En cas d'anomalie, l'administrateur peut
agir sur le serveur depuis la console en lançant des scripts.
Nous avons connu un certain nombre de problèmes
lors de l'installation et mieux vaut prévoir une formation
pour s'engager dans le déploiement d'Unicenter. De plus, le
logiciel ne dispose pas de fonctions de distribution automatique des
agents.
Côté notification des alertes, il définit
des niveaux de gravité en cas d'alertes réitérées
et non acquittées, mais la console de log des événements
est confuse. Les rapports générés avec le module
Report Builder sont trop techniques et leur lisibilité
médiocre. On peut limiter les accès avec une liste
d'utilisateurs mais il est impossible de chiffrer les échanges
entre la console, les agents et la base de données (pour la
sécurité, il faudra passer par SNMP). » -
Thibault Michel, Décision
Micro de Décembre 2001.
Caractéristiques principales :
Il se base sur le concept du Client/Serveur ITO qui
fournit une administration intégrée de la plupart des
objets constituant un système d'information tels que des
éléments systèmes, réseaux, applicatifs
ou bases de données.
Il gère et surveille les objets au moyen d'agents
intelligents fournis avec le produit. Avec l'aide de ces agents, il
est possible d'intercepter une vaste quantité de changements
d'états survenus dans le système d'information et d'y
répondre avec flexibilité et rapidité. Depuis
son introduction en 1993, IT/Operations
est devenu le coeur de la solution HP OpenView. Le serveur
d'administration est l'élément central d'IT/Operations.
Il renferme l'ensemble du logiciel, incluant la configuration
complète courante.
Il y a un serveur d'administration par installation
d'IT/Operations et ses tâches essentielles consistent à :
IT/Operations est divisé en deux composants de
base :
L'agent est localisé sur les systèmes gérés, appelés noeuds.
Il est principalement responsable de :
Le gestionnaire est localisé sur le serveur
d'administration, il :
IT/Operations permet de définir des filtres, des
valeurs seuil ("Threshold") et des intervalles de
surveillance ("monitoring intervals"). Si, par exemple, une
valeur seuil est dépassée, l'agent lance une action
automatique prédéfinie et/ou génère et
envoie un message standard pour alerter un opérateur à
la console d'administration centrale.
La fenêtre d'IT/Operations est une représentation
logique des noeuds administrés relatifs à un domaine
particulier de l'opérateur, c'est à dire les objets
administrés de l'opérateur.
L'opérateur peut utiliser la fenêtre pour
contrôler le statut de chaque noeud, et sélectionner les
noeuds ou les groupes de noeuds lors de l'exécution d'une
tâche spécifique.
Les noeuds administrés sont très flexibles
et autorisent une grande variété d'activités,
incluant :
Tivoli est une plateforme d'administration distribuée
reposant sur l'utilisation d'agents clients piloté par un
serveur.
Composé de différentes briques
logicielles, il adresse tous les secteurs de l'administration
systèmes (supervision, gestion de comptes, diffusion de
logiciels, administration de serveurs applicatifs, ...)
Il gère la supervision des systèmes et
applications.
Il optimise l'efficacité du département
informatique en l'aidant à identifier rapidement les
dysfonctionnements et goulots d'étranglement avec des
fonctions intelligentes pour corriger automatiquement les problèmes
au niveau de chaque composant.
Les logiciels Tivoli permettent de superviser depuis une
solution unique l'ensemble du système d'information en
partageant un même entrepôt de données et
bénéficiant d'une interface graphique et d'un
générateur de rapports communs.
Ils offrent de nouvelles fonctions pour corriger
automatiquement les problèmes au niveau de chaque composant
avant même qu'ils n'apparaissent.
Logiciel de supervision système et réseau.
Il permet de visualiser l'état des connexions et des services
installés sur les stations. Il peut fonctionner avec MRTG. Il
fonctionne sur pratiquement tous les
systèmes de type Unix (solaris, hpux, redhat, debian,
mandrake) et Windows 2000. Les clients existent pour Unix, Linux,
Windows, Novell Netware, MacOS.
La plate forme centrale est placée sous le
système de surveillance de Safety-Host. Ce système
permet de superviser en permanence le bon fonctionnement de
l'équipement par le biais des tests suivants :
En cas de non-réponse à un de ces tests,
l'équipe SafetyHost intervient pour mettre en œuvre les
procédures qui ont été prévues dans le
cadre de l'exploitation de l'équipement et consignées
dans le cahier de procédures.
Par le biais de cet outil, Safety-Host effectue
également une démarche proactive et d'anticipation sur
le serveur (prévisibilité de saturation espace
disque,...).
Ce logiciel utilise des scripts pour connaître en
temps réel l'état des différents composants de
votre machine et de votre réseau (connexion, charge cpu, taux
remplissage des disques, mémoire, trafic...).
Le gestionnaire du réseau installe donc un client
Big Brother sur chacun des
composants qu'il veut surveiller, et installe bien évidemment
sur une machine dédiée à la supervision
la partie serveur de Big Brother,
qui récoltera toutes les informations.
Pour chaque information, 3 états sont définis
:
Les seuils de chacun de ces états sont définis
lors de la configuration du client et du serveur BB.
Le serveur Big Brother
récupère donc ces infos et leur associe un code couleur
(vert, orange et rouge). Une page HTML est donc créée,
dans laquelle est inséré un tableau : en ligne les
différents postes supervisés et en colonne les données
à surveiller sur les machines, à l'intersection une
icône symbolisant l'état du matériel. Cette icône
est le lien vers une page Web détaillant le résultat du
script.
Le fond de ces pages HTML prend la couleur la plus
alarmante relevée lors de tous les contrôles, permettant
à l'administrateur du réseau de connaître tout de
suite l'état général du réseau.
L'administrateur peut être également
prévenu par mail lorsqu'un problème survient.
Il est également possible de connaître
l'historique des données sur la dernière journée
ou sur plusieurs jours.
Le logiciel Big
Brother ne nécessite aucune licence pour un usage non
lucratif, les entreprises peuvent donc l'utiliser gratuitement sous
réserve de l'enregistrement du produit auprès de
l'éditeur. Par contre les entreprises vendant le produit, un
service ou encore une aide en ligne, doivent acquérir la
licence aux tarifs suivants :
Serveur et Client sous Unix = 695 € / unité
Serveur Windows = 695 € / unité
Client Windows = 69 € / unité
Cette licence est dite « Better than Free »
( mieux que gratuite ) car si la somme demandée est trop
importante, des mesures de paiement peuvent être proposées
d'une part, et plus 10% de cette somme sera versée à
une des trois oeuvres caritatives mentionnées sur le site.
Pour
la transmission des données, Big Brother utilise le port
1984 pour communiquer avec les machines à surveiller.
Il
faut préciser que le code source de Big Brother est
disponible mais qu'il n'est PAS sous licence GPL (General Public
License).
Cette licence implique la liberté d'exécuter
le logiciel, et ce pour n'importe quel usage ; la liberté de
le modifier pour l'adapter à ses besoins (dans la pratique,
cela nécessite l'accès au code source) ; la liberté
de redistribuer des copies, soit gratuitement, soit contre
rémunération et la liberté de distribuer des
versions modifiées afin que la communauté du logiciel
libre puisse en profiter.
Voici un tableau résumé des logiciels open
source de supervision :
|
Des logiciels libres centrées sur la
supervision réseau.
|
|
Éditeur
|
|
Offre
|
|
Fonctions
|
|
Équipements acceptés
|
|
Prix à partir de (HT)
|
|
|
|
|
|
|
|
|
|
|
|
Alcôve
|
|
CAOBA
|
|
Supervision, intégration d'outils de
configuration tiers
|
|
Toutes marques
|
|
9 500 €
(62 000 F)
|
|
|
|
|
|
|
|
|
|
|
|
Université Berkeley
|
|
Ganglia
|
|
Supervision orienté grands réseaux,
clustering
|
|
Toutes marques
|
|
Gratuit
|
|
|
|
|
|
|
|
|
|
|
|
Aucun
|
|
Scotty
|
|
Supervision par SNMP, gestion des MIBs
|
|
Toutes marques
|
|
Gratuit
|
CAOBA répond
aux besoins de supervision des entreprises : supervision des
paramètres systèmes du réseau, tels que
routeurs, serveurs, stations, imprimantes; supervision des services
installés, tels que ftp, ssh, ldap, bases de données;
système de remontées d'alertes; auto découverte
du réseau et des services fonctionnels.
La solution d'Alcôve supporte SNMP et permet la
supervision d'environnements hétérogènes et
distribués. En effet, CAOBA est basé sur le logiciel
libre NetSaint qui met en oeuvre un système de plugins
fonctionnant sur l'ensemble des plates-formes de type Unix (HP-UX,
AIX, Linux, Solaris, les systèmes BSD...) et Windows (NT,
2000, XP).
Pour chacun des éléments d'infrastructure
et ses composants (CPU, espace disque disponible...) et pour chacun
des services (serveurs de fichiers, d'authentification, d'annuaires,
de bases de données...), CAOBA
permet la configuration de routines de vérification à
intervalles réguliers et d'alertes associées.
La solution de supervision CAOBA
offre la possibilité aux administrateurs réseaux de
recevoir les alertes sous plusieurs formes : sur une console de
surveillance, par email, ou encore via SMS ou pager.
Chaque élément physique à
superviser est rattaché à un groupe (ex : Routeurs,
serveurs Linux, serveurs NT...) et le système d'alertes
autorise la création de groupes de destinataires des messages.
Il est ainsi possible à l'administrateur principal de déléguer
la surveillance des éléments du réseau de son
choix.
La consultation des reportings s'effectue via une
interface WEB. Les éléments de reporting proposés
par la solution sont des vues topologiques du réseau, des
tableaux de consultation des événements par éléments,
par groupes, par services, par types d'alertes.
L'offre CAOBA
proposée par Alcôve comprend en standard :
La supervision des paramètres systèmes :
utilisation du CPU, occupation des disques, surveillance de l'état
des processus et de leur nombre, utilisation du swap, nombre
d'utilisateurs, analyse des logs.
La supervision des services : serveur de fichiers (ftp,
smb), serveur d'authentification, serveur web (http/https), serveur
de noms de domaines, serveur de mails, serveur d'annuaires, serveur
de news, serveur de temps, serveur de bases de données
PostgreSQL, Mysql et Microsoft SQLServer, Exchange, etc..., ainsi
que le monitoring Hardware pour les serveurs Linux.
L'auto découverte du réseau et des
services fonctionnels.
En termes de services associés à cette
offre logicielle, Alcôve propose en standard :
L'offre CAOBA standard, proposée, est prévue
pour 40 services et une centaine de postes clients. Alcôve propose également en options :
Alcôve a intégré un grand nombre de
logiciels libres tels que
Linux Debian, NetSaint, IPScan, NMap, NMAp to NetSaint,
NSclient, et bien d'autres encore.
Ganglia est une base de données distribuée,
contenant l'état actuel des machines participantes. Utilisé
avec rrdtool, de jolis graphiques permettent de suivre l'état
des systèmes sur quelques minutes, semaines ou mois.
Ce logiciel de
surveillance de clusters (grappes) présente les informations
sous la forme d'un vaste tableau comportant une ligne par noeud et
une colonne par paramètre. Cette présentation permet
d'obtenir une vue instantanée de l'état de l'ensemble
des machines. Le rafraîchissement de cette vue se fait soit à
intervalles de temps réguliers (quelques secondes par défaut),
soit à la demande de l'utilisateur.
Les principales limitations de ce logiciel, apparaissent
avec l'augmentation du nombre de machines prises en compte. Au delà
d'une quarantaine de lignes environ, les informations ne sont plus
très lisibles, et il est nécessaire de faire défiler
les fenêtres pour voir l'ensemble des machines.
Un autre point ignoré par cet outil est
l'historique des informations. La vue donnée correspond à
un instant précis et il n'est pas possible de voir l'évolution
d'un paramètre au cours du temps.
Voici un tableau de
ses composants principaux :
|
Composant
|
Description
|
|
Démon du client Ganglia
(gmond)
|
Ce démon doit être
installé sur tous les noeuds que l'on veut surveiller. Il
récupère différentes données puis les
exporte par l'intermédiaire de XML.
|
|
Démon du serveur Ganglia
(gmetad)
|
Le démon du serveur de
Ganglia réceptionne et fusionne les données en
provenance de sources multiples (des clients), stocke ces données
numériques volatiles dans des bases de données
locales et présente une vue simple XML de tous les
clusters qui sont
surveillés.
|
|
Interface web de Ganglia
|
L'interface graphique de Ganglia
emploie un serveur web PHP pour présenter les données
rassemblées par le démon serveur à un
navigateur.
|
Ganglia gère
les systèmes Linux, Solaris, FreeBSD, AIX, IRIX, Tru64, HPUX,
MacOS X et Windows mais la station de supervision ne s'installe que
sous Unix/Linux. Toutes les données sont échangées
dans les formats XML/XDR pour en assurer l'extensibilité et la
portabilité maximum.
L'ajout de "sondes"
est très facilement réalisable à l'aide de
simples scripts bash ou Perl, par exemple. A la rédaction de
ce rapport, il n'y avait pas encore beaucoup de documentation sur ce
produit nouvellement sorti.
Scotty est un outil de supervision de réseau. Il
est livré avec une interface graphique : " tkined ".
Il permet une représentation graphique des noeuds d'un réseau.
Il permet également l'analyse du fonctionnement des noeuds à
l'aide du protocole SNMP. Scotty est une distribution incluant deux
composants.
Le premier est Tnm Tcl Extension. Il permet un accès
aux sources d'informations des réseaux par une invite de
commande Tcl. Il utilise les protocoles suivants : SNMP (SNMPv1,
SNMPv2c, SNMPv2u avec accès aux définitions de MIB),
ICMP, DNS, HTTP, SUN RPC, NTP et UDP.
Le deuxième composant est Tkined : un éditeur
de réseau s'appuyant sur Tnm. Il peut découvrir le
réseau et permet entre autre l'interrogation de MIB.
Pour les utilisateurs plus avancés, quelques
scripts Unix ou un programme en C permettent de surveiller des
applications. Ceux-ci peuvent être facilement intégrés
dans Tkined.
Une première étape a consisté à
éliminer tous les produits payants pour des raisons d'économie
du fait que la hiérarchie désirait un produit simple,
efficace et surtout gratuit tant pour le logiciel que pour éviter
les frais liés à la formation.
En effet, sur des produits plus complets et, dans
certains cas, trop complexes, il est nécessaire d'investir en
plus dans la formation des utilisateurs et dans le transfert de
compétences.
Il ne restait donc, après cette étape, que
4 logiciels en concurrence : Big Brother, Ganglia, Scotty et Nagios
(anciennement Netsaint).
La deuxième étape a consisté à
évaluer les possibilités des différents
logiciels libres en établissant un comparatif entre les
besoins et les possibilités offertes par ces solutions.
Big Brother n'a pas été retenu pour les
raisons suivantes :
Ganglia n'a pas été retenu pour les
raisons suivantes :
Scotty n'a pas été retenu pour les raisons
suivantes :
Nagios fut retenu pour les raisons suivantes :
L’avenir de l’administration passera par
l’Internet car il facilite l’administration à
distance. Il se dégage déjà un standard autour :
Un troisième standard émerge autour de
JAVA:
Ce stage a été véritablement
enrichissant de multiples manières :
Au cours de ce stage, j'ai pu réellement
appréhender ce qu'était le travail d'un administrateur
réseau n'ayant que peu d'idées sur tout ce que cela
demandait en termes de compétences techniques, de
disponibilité et de relationnel.
De multiples casquettes sont à gérer :
administration courante, relais technique entre les utilisateurs et le
système informatique en place,
Une excellente connaissance de son parc et des
possibilités qu'il offre est indispensable tant sur le plan
matériel que logiciel.
La notion d'anticipation et de veille technologique est
importante et rassurante tant pour la hiérarchie que pour tous
les utilisateurs.
On sous estime souvent l'apport relationnel qu'un stage
peut apporter.
Personnellement, j'y ai compris que plus la
communication était présente entre les différents
acteurs d'un service, plus la qualité du travail progressait.
Des échanges permanents contribuent aussi à
acquérir des compétences et un savoir-faire par la
transmission d'idées et de vécus.
Les relations avec les utilisateurs m'ont permis de voir
que, parfois, ce qui est évident pour un informaticien ne
l'est pas pas pour celui qui est novice et qu'il est nécessaire
de poser des questions précises pour cerner le problème.
Il est difficile de décrire toutes les phases par
lesquelles on passe lors d'un stage où, chaque jour, on
apprend de nouvelles choses.
J'ai noté l'importance de se remettre en question
de manière régulière dans le but d'évoluer
et d'acquérir les techniques indispensables à ce métier.
Certaines qualités sont indispensables à
travailler comme l'humilité, la concentration, la
communication et la diligence, tout cela pour fournir un travail
sérieux et de qualité.
L'investissement paraît important au départ
mais c'est parce que l'on ne possède pas assez les techniques
et les compétences nécessaires pour y arriver.
La formation initiale est plus que suffisante, mais en
fait, rien ne vaut la mise en situation réelle pour mieux
comprendre le fonctionnement d'une entreprise, de ses services et de
son architecture informatique propre, fruit d'une adaptation
permanente aux besoins recensés.
En résumé, ce stage m'a permit d'évoluer
dans ma compréhension de la technique et des individus,
d'acquérir des compétences recherchés et de
constituer un tremplin adéquat pour une carrière dans
l'administration réseau.
Le protocole SNMP (Simple Network Management Protocol)
est un protocole d'administration réseau composé de
trois types d'éléments :
- des AGENTS sur les hôtes distants chargés
d'enregistrer en permanence les informations du système local
dans la MIB
- une MIB (Management Information Base), base de donnée
contenant les valeurs que l'on désire récupérer.
- une NMS (Network Management Station) capable d'aller
chercher et d'interpréter les données.
Schéma SNMP
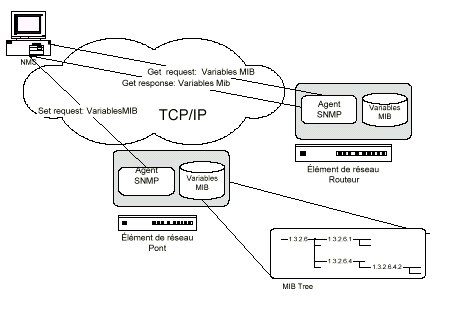
Pour interroger une MIB, il existe 5 commandes de base
sous linux : snmpget, snmpgetnext, snmpset, snmpwalk et snmptrap
cette dernière permettant l'envoi d'alertes à la NMS
sur la base d'une valeur d'une variable présente dans la MIB.
Voici un exemple en ligne de commande :
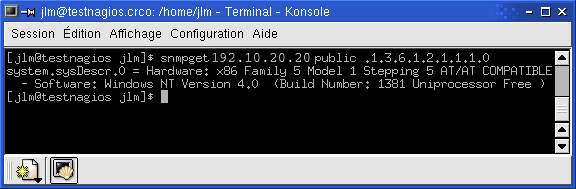
Cette commande effectue une requête dans
l'arborescence de la table MIB à partir de l'adresse IP de
l'hôte (ici 192.10.20.20). Ici, on demande une description du
système telle qu'elle est enregistrée dans la
table MIB
du serveur concerné.
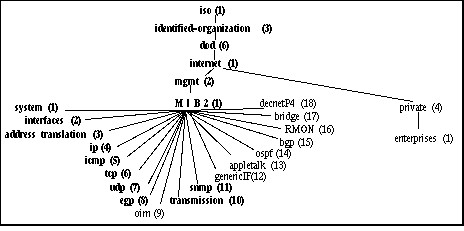
Il est à noter que dans la MIB par défaut
d'un serveur Windows NT, on peut accéder à deux
branches de l'arborescence principale, l'une est nommée
mib-2
(contenant des informations sommaires sur l'OS, les interfaces et les
protocoles) et l'autre est nommée lnmib (contenant des
informations sur les services réseaux actifs).
On peut bien sûr ajouter des branches
supplémentaires pour augmenter le nombre de valeurs à
contrôler. Pour cela, on peut utiliser celle qui est développée
par Gart Williams (site :
http://www.snmp4tpc.com/) disponible
gratuitement en téléchargement (sous le nom de PERFMIB).
Il a développé la branche des compteurs du
système Microsoft (.1.3.6.1.4.1.311.1.1..3.1.1.*). On a ainsi
accès aux informations de mémoire, de charge CPU,
d'espace disque, etc...
Pour les serveurs 2000, il existe par défaut une
branche de la mib-2 Standard, appelée "host"
(.1.3.6.1.2.1.25.*), qui contient certains compteurs (ou valeurs)
système comme l'uptime, l'utilisation de la mémoire, l'espace
disque, la charge du processeur,...
Gart Williams en a développé une autre
pour Windows 2000 (toujours appelée PERFMIB) mais dont le
nombre de compteurs est plus restreint que pour les serveurs NT. Pour
avoir tous les compteurs disponibles, il est nécessaire de
payer une licence.
Pour les serveurs Citrix, c'est identique aux serveurs
Windows 2000. L'avantage est que l'on peut générer un
large variété de traps.
Schéma d'une MIB standard
Il faut d'abord télécharger les fichiers
suivants sur le site www.rpmfind.net par exemple :
|
nagios-1.0-2mdk.i586.rpm
|
-> paquetage pour
installer nagios
|
|
nagios-www-1.0-2mdk.i586.rpm
|
-> paquetage pour
l'interface web
|
|
nagios-plugins-1.3b1-2mdk.i586.rpm
|
-> paquetage de modules
nécessaires
|
|
fping-2.4b2-2mdk.i586.rpm
|
-> paquetage pour
utiliser ICMP
|
|
libradius0-0.3.2-1mdk.i586.rpm
|
-> paquetage de
librairies pour Radiusclient
|
|
ntp-4.1.1-2mdk.i586.rpm
|
-> paquetage pour
utiliser NTP
|
|
ucd-snmp-utils-4.2.3-4mdk.i586.rpm
|
-> paquetage pour
utiliser SNMP
|
|
libsnmp0-4.2.3-4mdk.i586
|
-> fichier de librairies
pour protocole SNMP
|
Ensuite, on clique droit sur chacun des paquetages :
Ouvrir avec... -> Installateur de logiciels.
Il existe un ordre d'installation : d'abord
nagios-plugins puis nagios-1.0 enfin le reste des paquetages. Voici
l'arborescence de l'installation de Nagios :
|
/etc/nagios
|
-> répertoire
contenant les fichiers de configuration
|
|
/usr/lib/nagios
|
-> répertoire
contenant CGI + modules (les « check »)
|
|
/var/log/nagios
|
-> répertoire
contenant les fichiers de logs
|
|
/var/spool/nagios
|
-> répertoire du
fichier de commande externe
|
|
/usr/share/nagios
|
-> répertoire de
sons, images et documentation
|
|
/etc/rc.d/init.d/nagios
|
-> fichier de démarrage
(du daemon)
|
|
/var/run/nagios
|
-> fichier indiquant le
PID du programme
|
|
/usr/sbin/nagios
|
-> fichier exécutable de
nagios
|
|
/var/lock/subsys/nagios
|
-> fichier système
bloqué en cours d'exécution
|
|
/etc/httpd/conf/nagios-httpd.conf
|
-> fichier d'alias
|
L'utilitaire
d'installation demandera peut-être d'autres fichiers pour
satisfaire les dépendances.
Nagios a également besoin d'un Serveur Web. Il
faut vérifier que l'on possède bien le paquetage pour
le serveur Web Apache. Ensuite, qu'il fonctionne, en vérifiant
que le daemon ou processus httpd soit actif. On teste enfin le tout
en tapant l'url suivante dans un navigateur (Mozilla) :
http://localhost/ -> une jolie page d'accueil doit
s'afficher !
S'il est nécessaire de (re)démarrer les
daemons httpd et nagios. On peut le faire de deux façons :
A ce stade, on peut vérifier que l'on a accès
à la page d'accueil de nagios en tapant cette url :
http://localhost/nagios/
Comme tout logiciel à code source ouvert, Nagios
est peut-être promis à un bel avenir tant que des
développeurs continueront à le faire évoluer.
Cette évolution est logiquement catalysée
par le nombre d'utilisateurs et par une communauté désirant
s'affranchir des solutions payantes.
1°) Ne pas lancer Nagios en tant que « root »
; il faut ajouter au fichier de configuration un « user »
et un « group » qui ne possède pas tous
les droits.
2°) Désactiver les commandes externes si on
ne les utilise pas.
3°) Accéder à l'interface Web via une
authentification.
4°) Utiliser des chemins complets dans la définition
des commandes (évite le lancement de « chevaux de
Troie »).
5°) Cacher les informations sensibles à
l'aide des macros $USERx$ : les CGI lisant les fichiers de
configuration, il est recommandé de ne pas y laisser
d'informations sensibles (user, password) et de les cacher par
l'utilisation de macros définit dans les fichiers de
ressources non parcourut par les CGI et dont on peut restreindre les
droits.
Il est possible d'augmenter sensiblement les
performances de Nagios de différentes façons :
1°) Préférer l'utilisation des contrôles
passifs aux contrôles « normaux » permet
de limiter la charge induite par le traitement des résultats.
2°) Utiliser l'interpréteur Perl intégré
accélérera les traitements.
3°) Optimiser la configuration matérielle de
la station de surveillance en particulier l'accès aux disques
qui peuvent être un goulet d'étranglement
Il est possible d'exécuter des commandes
optionnelles à chaque fois qu'un changement d'état a
lieu. Cela permet de résoudre les problèmes de manière
préventive avant que quelqu'un ne reçoive une
notification. L'exemple le plus évident étant de
vouloir redémarrer un service à la première
alerte.
Une seconde utilité est celle d'enregistrer les
événements relatifs aux hôtes ou aux services
dans une base de donnée externe.
Lorsque l'on désire accéder à des
portions du réseau inaccessible depuis la station de
surveillance ou encore lorsque celle-ci est défaillante, on
peut implémenter Nagios de manière à ce que
d'autres stations prennent le relais.
C'est un fonctionnement maître esclave(s) dans le
cas d'une défaillance et en pool dans le cas de multiples
réseaux.
Le but est de répartir l'excès de charge
induite par les contrôles de services du processus central
Nagios sur un ou plusieurs serveurs répartis. Cette possibilité
ne concerne que les entreprises qui possèdent des centaines
voire des milliers d'hôtes.
Le serveur central écoute simplement les
résultats des contrôles alors que ce sont les serveurs
répartis qui ordonnancent les contrôles.
Dans le cas où l'on veut connaître l'état
général de services groupés ou d' hôtes
groupées, il existe un plugin permettant de le faire.
On peut le faire de deux manières : superviser
individuellement les éléments du cluster ou superviser
en tant qu'entité collective.
Nagios gère très bien le clustering avec
son plugin « check_cluster ».
Il existe d'autres possibilités exploitables
comme le support de base de données, la détection du
balayage de port en combinant Nagios et le logiciel Portsentry, les
alertes de rejet de connexions par les enveloppes TCP/IP,...
Les derniers développements sont disponibles sur
le site officiel de Nagios :
http://www.nagios.com
Le protocole SNMP s'est enrichi, depuis sa version 1 de
nombreuses évolutions décrites ci-après.
La version 2 améliore le protocole sous 6 aspects
distincts :
Le problème de SNMPv2 c'est qu'il n'existe
actuellement aucun standard largement accepté, à la
différence de SNMPv1. Il n'est pas facile de rencontrer des
versions de SNMPv2 d'agents ou de software qui utilisent les
nouvelles commandes. Il faut laisser passer le temps et voir ce qu'il
en adviendra dans le futur proche.
1 #!/usr/bin/perl
2 my $ip_address = shift || &usage();
3 my $oid = ".1.3.6.1.4.1.77.1.2.3.1.1.7.83.112.111.111.108.101.114";
4 my $return_value;
5
6 $return_value = system("/usr/lib/nagios/plugins/check_snmp -H $ip_address
7 -C 'public' -o $oid -l 'Service Spooler'");
8
9 if ( $return_value != 0 ) {
10 $return_value = 2;
11 }
12
13 exit $return_value;
14
15 sub usage {
16 print "Arguments requis !\n";
17 print "\n";
18 print "Plugin en Perl testant le Service Spooler pour Nagios et NT OS\n";
19 print "Usage: check_print_nt.pl <adresse ip>\n";
20 print "\n";
21 print "<addresse ip> = Addresse IP du serveur NT à interroger.\n";
22 exit -1;
23 }
Quelques explications :
ligne 1 : on utilise
l'interpréteur Perl
lignes 2-4 :
déclaration et affectations des variables utilisées
lignes 6,7 : on fait
exécuter d'abord le script "check_snmp"
(plugin de Nagios) pour récupérer ensuite une valeur de
retour dans la variable "$return_value", il est aussi
possible de faire directement un <snmpget AdresseIP communauté
OID> et de récupérer une valeur de retour dans
"$return_value".
Cette variable contient soit
la valeur 0 pour un état OK, soit une autre valeur pour les
états UNKNOWN,CRITICAL,UNREACHABLE.
lignes 9-11 : si la
valeur de retour est différente de 0, elle prendra la valeur 2
pour un état CRITICAL
ligne 13 : on retourne
la nouvelle valeur à Nagios
lignes 15-23 :
procédure de deboggage en mode console appelée lorsque
le paramètre est incorrect
Tous droits Réservés - Juin 2003 - MERAT Jean-Luc
Retour à l'accueil